
robots.txt is a search engine spider protocol file, its purpose is to inform the search engine spiders which pages of your website can be crawled and which pages cannot be crawled.robots.txt is a plain text file that follows the robot exclusion standard, consisting of one or more rules, each rule can prohibit or allow specific search engine spiders to crawl the specified file paths under the website.If you do not set it, all files will be allowed to be captured by default.
robots.txt is a search engine spider protocol file, its purpose is to inform the search engine spiders which pages of your website can be crawled and which pages cannot be crawled.robots.txt is a plain text file that follows the robot exclusion standard, consisting of one or more rules, each rule can prohibit or allow specific search engine spiders to crawl the specified file paths under the website.If you do not set it, all files will be allowed to be captured by default.
The robots.txt rules include:
User-agent: The user agent (UA) identifier, you can view it here.
Allow: Allow access to crawling.
Disallow: Prevent access to crawling.
Sitemap: Site map. There is no limit on the number of entries, you can add multiple sitemap links.
# : Comment line.
This is a simple robots.txt file containing two rules.
User-agent: YisouSpider
Disallow: /
User-agent: *
Allow: /
Sitemap: /sitemap.xml
User-agent: BaiduSpider means that the rules for user agents such as "YisouSpider" (a search engine spider of Yisou) can also be set to bingbot (Bing), Googlebot (Google), and so on.The proxy names of other search engine crawlers can be viewed here.
Disallow: / means 'Disallow access to all content'.
The meaning of the line is: rules for all user agents (* is a wildcard).All user agents can crawl the entire website. It does not matter if this rule is not specified; the result is the same;The default behavior is that the user agent can crawl the entire website.
The meaning of the line 'Sitemap:' is: the path to the sitemap file of the website is./sitemap.xml.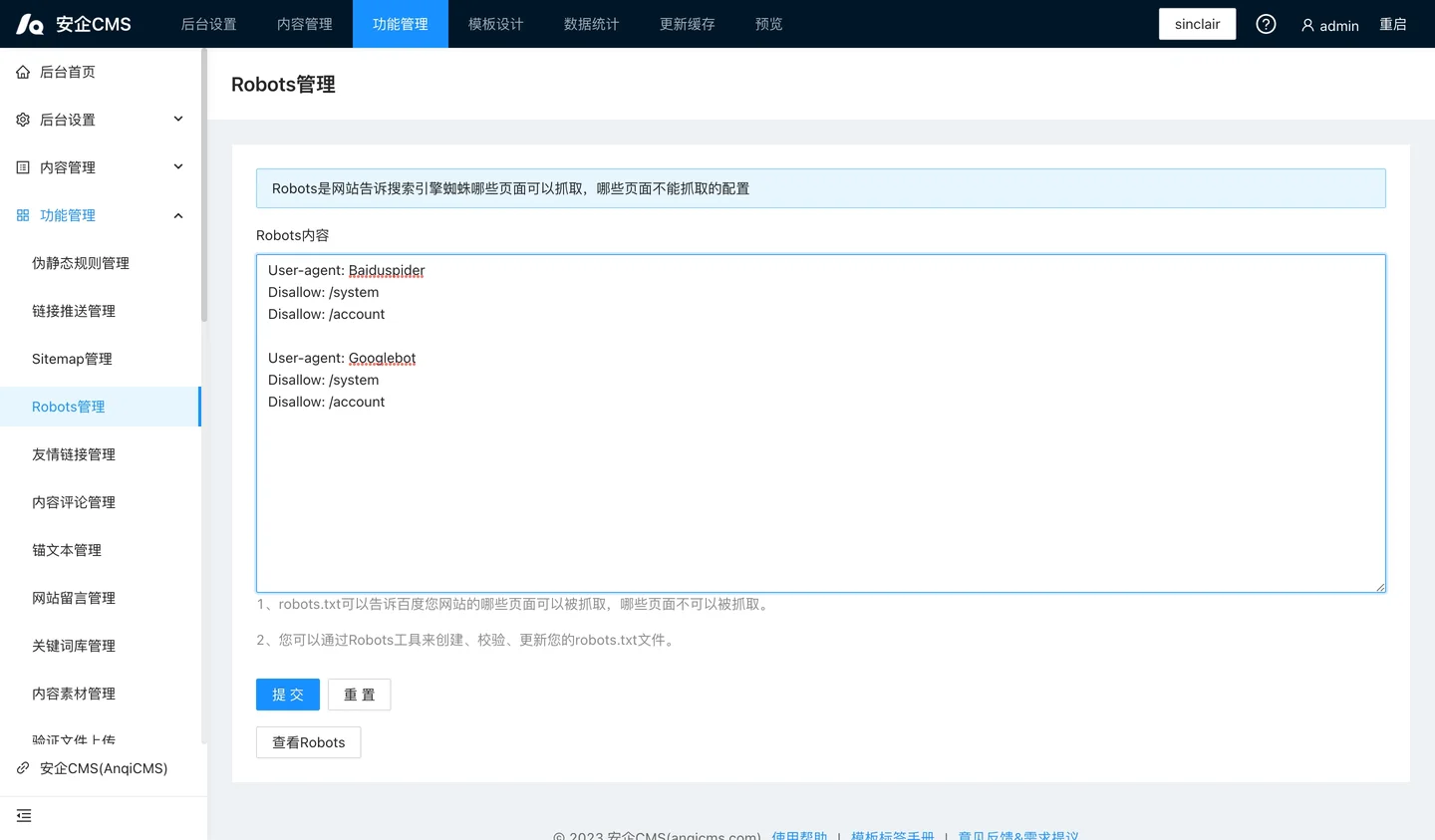

Sitemap is the map of a website, which can gather categories, article content, pages, tags, and other information together for display, making it convenient for search engine spiders to quickly crawl all the publicly available content of the website.Sitemap is an important part of a website's SEO, expanding its visibility on search engines.

The link push function supports automatic push of new and updated content on the website to search engines in real time, allowing search engines to discover the updated content of the website in a timely manner and promote the inclusion of the website.The search engine push feature supports the active push of Baidu search and Bing search, while other search engines do not have the active push feature, but some search engines can still use JS push.

Friend link, also known as website exchange link, refers to placing the link of the other website on your own website, which also belongs to the form of external links.Establishing good friend links can improve the weight of your website and the ranking of your website's keywords.Friendship links are more beneficial for website ranking than ordinary external links.
